Let Vanna.AI write your SQL for you
The fastest way to get actionable insights from your database just by asking questions
Vanna Products
Enterprise-grade AI solutions for data retrieval, analysis, and text-to-SQL capabilities
Vanna Cloud
Enterprise-ready data retrieval and analysis platform with zero setup required. Train AI on your specific data environment, industry, and company, ensuring accurate insights and responses for business users. Robust governance controls, team permissions, and instant database connectivity get you from setup to insights in minutes.
Get Started for FreeVanna Self-Hosted Enterprise
All the capabilities of Vanna Cloud deployed within your own infrastructure. Maintain complete data sovereignty with deployment in your VPC and compatibility with your preferred cloud LLM provider. Perfect for organizations with strict compliance requirements.
Contact UsVanna Embedded
Leverage the full power of Vanna Cloud through our API, bringing enterprise-grade database AI interactions to your existing applications and agent frameworks. Access all of Vanna Cloud's security, monitoring, and observability controls while providing a seamless, native experience for your users. Add sophisticated data capabilities without building from scratch.
Get Started for FreeVanna OSS
For teams that need maximum flexibility, our open-source foundation empowers developers to integrate powerful text-to-SQL capabilities into any application. Complete customization control for those who want to build on the same proven framework that powers our enterprise offerings.
Read the Docs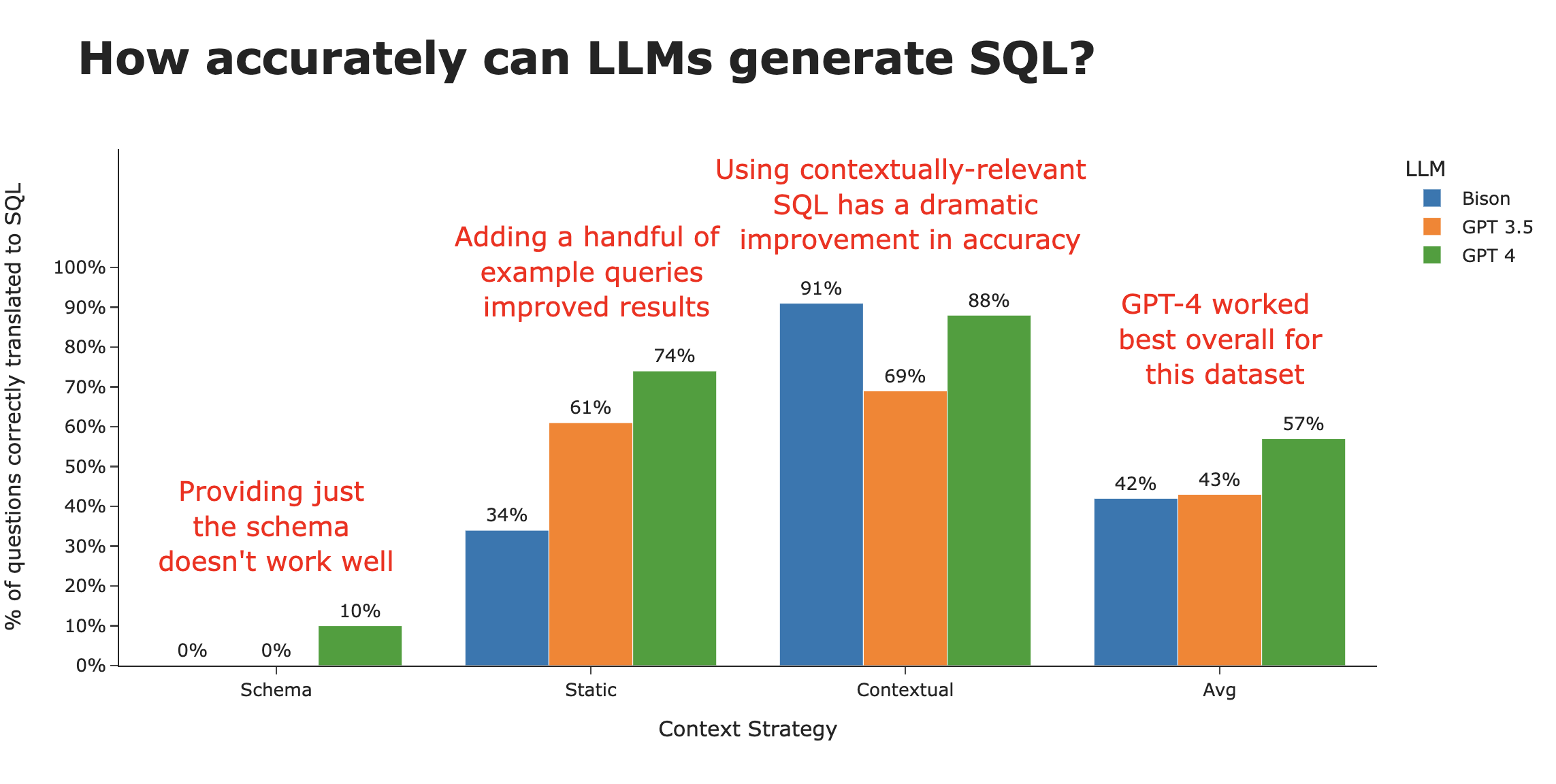
Whitepaper: How to get high SQL accuracy rates using AI
TLDR: It all has to do with the training data you give it, which is what helps with.
"Why use AI to chat with your database in the first place? To start, it allows you spend less time writing SQL and more time generating insights on your data. You no longer have to be an expert in SQL to get information from the database. And if you are an expert, save some time writing a query when you can just ask for it. In fact, everyone benefits by being able to ask the database about business questions and getting the answer; have Vanna find the relevant tables and columns across your data estate."

Why ?
Open-Source
The Vanna Python package and the various frontend integrations are all open-source. You can run Vanna on your own infrastructure.
High accuracy on complex datasets
Vanna’s capabilities are tied to the training data you give it. More training data means better accuracy for large and complex datasets.
Designed for security
Your database contents are never sent to the LLM unless you specifically enable features that require it. The metadata storage layer only sees schemas, documentation, and queries.
Self learning
As you use Vanna more, your model continuously improves as we augment your training data.
Supports many databases
We have out-of-the-box support Snowflake , BigQuery, Postgres, and many others. You can easily make a connector for any database.
Choose your front end
Start in a Jupyter Notebook. Expose to business users via Slackbot, web app, Streamlit app, any other frontend. Even integrate in your web app for customers.
Pricing
The core Vanna package is open-source and configurable.
We offer a hosted application.
 Vanna.AI
Vanna.AI
The fastest way to get insights from your database just by asking questions
Enterprise customization.
Many large enterprises need customization in deployment. Vanna is open-source so you can do this yourself. If you need help, contact us and we'll connect you with experienced developers.
- Any LLM